

Harmen van Rossum
November 11, 2024
November 11, 2024

We're Funding the Creation of an Open-Source Antibody Dataset
Today, we're excited to announce a new initiative: we're funding the creation of new NGS datasets of antibody binders. All of this data will be freely available on the internet.
There's just one question... Which targets should we select for antibody binding? This is where you can contribute! You'll find the submission link at the bottom of this post.
The Opportunity: Better Models for Better Drugs
Antibody discovery typically begins with generating vast numbers of antibodies (through methods such as llama immunization campaigns, naive libraries, or synthetic libraries). These antibodies then go through a selection process called "panning": imagine it like panning for gold, where we're searching for the few valuable pieces among many. We repeatedly expose our antibody collection to the target molecule we're interested in. The antibodies that stick to the target are kept, while the others are washed away. With each round, we get a more concentrated collection of antibodies that bind well to our target. When we sequence these antibodies using NGS technology at each stage, we get rich datasets that can be used for further optimization, especially when combined with machine learning. However, surprisingly few such large-scale datasets are publicly available. In an era increasingly focused on AI antibody design, this gap needs to be addressed!
The Solution: Your Help
We're inviting researchers and scientists to join us in accelerating antibody discovery and, ultimately, the development of improved drugs.
We're asking you to submit potential targets for which you'd like to have NGS data. We're looking for targets that are proteins or peptides with the following characteristics:
Soluble
Stable
Easy to manufacture and safe to handle
Either mono- or multi-specific
Preferably addressing underserved areas, such as orphan or poverty-related diseases (Don't worry if you're unsure whether your target meets all criteria - we can assess this later)
We'll follow the process described above: conducting a large antibody panning study and making the NGS results freely available online!
By sharing target ideas that meet these criteria, you'll contribute to an open dataset that could accelerate AI-based discovery. We'll handle the experiments and publish the resulting data for everyone to use and build upon.
How to Contribute:
Simply visit https://cradlebio.typeform.com/targets to submit your target ideas. Every submission brings us closer to achieving faster, more effective antibody discoveries.

Today, we're excited to announce a new initiative: we're funding the creation of new NGS datasets of antibody binders. All of this data will be freely available on the internet.
There's just one question... Which targets should we select for antibody binding? This is where you can contribute! You'll find the submission link at the bottom of this post.
The Opportunity: Better Models for Better Drugs
Antibody discovery typically begins with generating vast numbers of antibodies (through methods such as llama immunization campaigns, naive libraries, or synthetic libraries). These antibodies then go through a selection process called "panning": imagine it like panning for gold, where we're searching for the few valuable pieces among many. We repeatedly expose our antibody collection to the target molecule we're interested in. The antibodies that stick to the target are kept, while the others are washed away. With each round, we get a more concentrated collection of antibodies that bind well to our target. When we sequence these antibodies using NGS technology at each stage, we get rich datasets that can be used for further optimization, especially when combined with machine learning. However, surprisingly few such large-scale datasets are publicly available. In an era increasingly focused on AI antibody design, this gap needs to be addressed!
The Solution: Your Help
We're inviting researchers and scientists to join us in accelerating antibody discovery and, ultimately, the development of improved drugs.
We're asking you to submit potential targets for which you'd like to have NGS data. We're looking for targets that are proteins or peptides with the following characteristics:
Soluble
Stable
Easy to manufacture and safe to handle
Either mono- or multi-specific
Preferably addressing underserved areas, such as orphan or poverty-related diseases (Don't worry if you're unsure whether your target meets all criteria - we can assess this later)
We'll follow the process described above: conducting a large antibody panning study and making the NGS results freely available online!
By sharing target ideas that meet these criteria, you'll contribute to an open dataset that could accelerate AI-based discovery. We'll handle the experiments and publish the resulting data for everyone to use and build upon.
How to Contribute:
Simply visit https://cradlebio.typeform.com/targets to submit your target ideas. Every submission brings us closer to achieving faster, more effective antibody discoveries.
Recent posts
Optimizing Cetuximab: An update on our win of the Adaptyv 2024 competition
Mar 31, 2025
Mar 31, 2025
Next-level high throughput workflows: Gotta tag 'em all
Mar 6, 2025
Mar 6, 2025

Cradle Announces Launch of Advanced Biotechnology Report with Industry Coalition
Mar 11, 2025
Mar 11, 2025
SLAS 2025: A Peek at The Future of Lab Automation
Feb 26, 2025
Feb 26, 2025
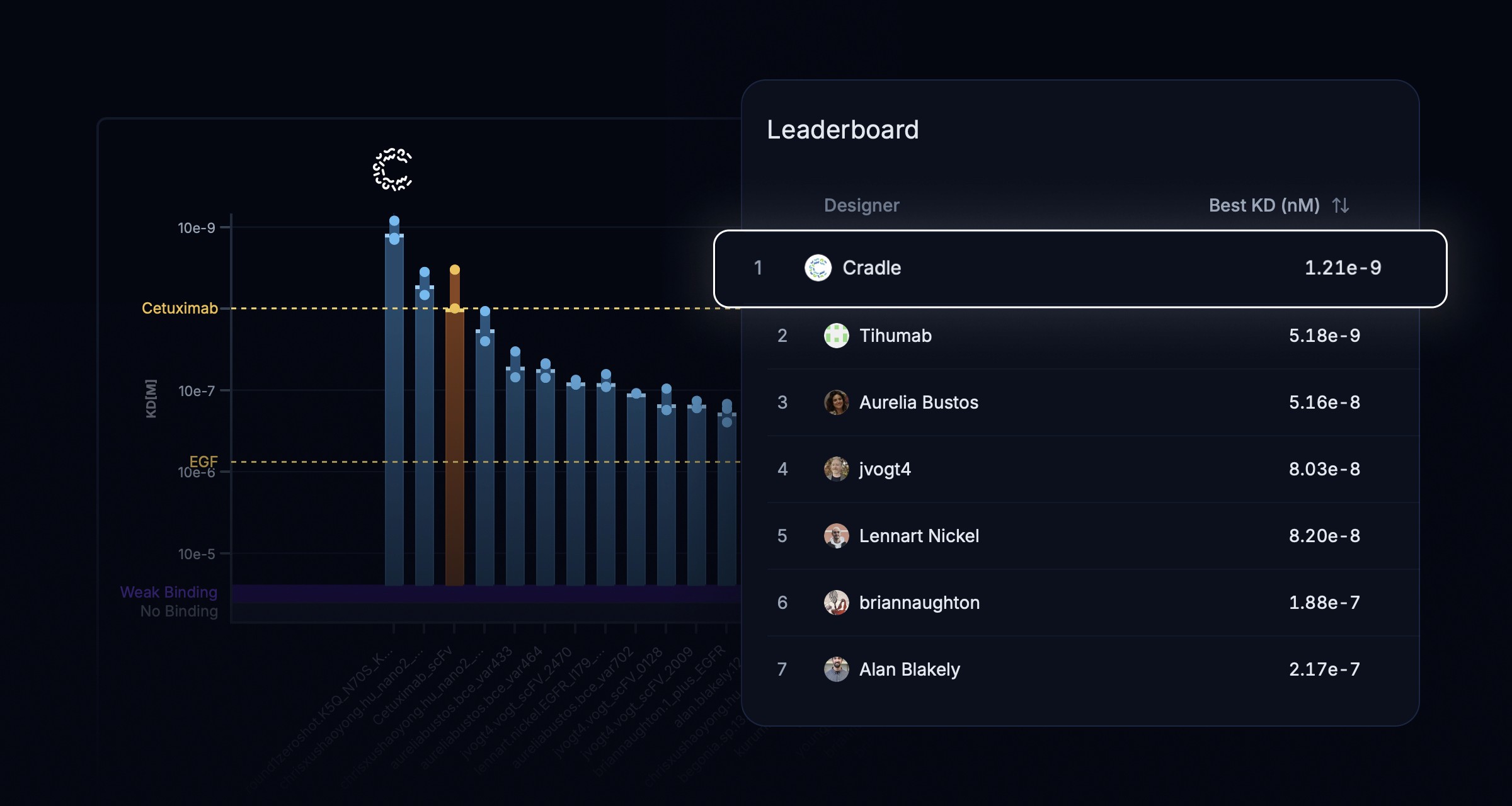
8x improvement in EGFR binding affinity: winning the Adaptyv Bio protein design competition
Dec 10, 2024
Dec 10, 2024
Subscribe to updates
Get new posts and other Cradle updates directly to your inbox. No spam :)
Built with ❤️ in Amsterdam & Zurich
Built with ❤️ in Amsterdam & Zurich